本文算是上一博文 Linux 内核学习笔记:预备知识之“目标文件”的续篇,主要说明操作系统如何将可执行目标文件加载到进程的虚拟地址空间并执行。虚拟地址空间的阐述将会穿插在这过程中。最后,还对缺页异常进行阐述。
加载
在《深入理解计算机系统》中,作者给出了加载(loading)的一个定义:
将程序拷贝到存储器并运行的过程叫做加载。
接下来我们先来看一下加载器的工作概况。
加载器工作概况
试想我们执行这样一个可执行目标文件a.out:
1 | $ ./a.out |
在调用应用程序的 main 函数前,操作系统私底下做了些什么工作?
实际上,在应用程序的 main 函数被调用前,对可执行目标文件a.out的加载是由操作系统的加载器来完成的。加载器的工作概况如下(摘自《深入理解计算机系统》第 7.9 节“加载可执行目标文件”):
Unix 系统中的每个程序都运行在一个进程上下文中,有自己的虚拟地址空间。当外壳运行一个程序时,父外壳进程生成一个子进程,它是父进程的一个复制品。子进程通过 execve 系统调用启动加载器。加载器删除子进程现有的虚拟存储器段,并创建一组新的代码、数据、堆和栈段。新的栈和堆段被初始化为零。通过将虚拟地址空间中的页映射到可执行目标文件的页大小的片(chunk),新的代码和数据段被初始化为可执行目标文件的内容。最后,加载器跳转到
_start地址,它最终会调用应用程序的 main 函数。除了一些头部信息,在加载过程中没有任何从磁盘到存储器的数据拷贝,直到 CPU 引用一个被映射的虚拟页才会进行拷贝,此时,操作系统利用它的页面调度机制自动将页面从磁盘传送到存储器。
这段描述说的非常清晰,有这么几点比较重要的:
- 父进程(外壳,即 shell)派生一个子进程。
- 子进程通过
execve系统调用执行可执行目标文件,并陷入内核启动加载器,开始真正的加载工作。 - 加载器对子进程虚拟地址空间进行初始化,即删除子进程现有的虚拟存储器段,并创建一组新的代码、数据、堆和栈段,最后将新的代码和数据段初始化为可执行目标文件的内容。
- 加载器跳转到
_start,最终调用应用程序 main 函数。
下文将按照这四点进行叙述。
进程派生
这部分其实并不是加载器做的事情,但为了连贯和理解方便,特加上。《Unix 环境高级编程》(第三版)第 8 章是这部分主要参考资料。
fork 函数
在 Linux 中,进程派生需要用到函数fork:
1 |
|
fork函数调用一次,返回两次。它在调用进程(称为父进程)中返回一次,返回值是新派生进程(称为子进程)的进程ID号;在子进程中返回一次,返回值为0。因此,返回值本身告知当前进程是子进程还是父进程。fork在子进程返回 0 而不是父进程的进程 ID 的原因在于:任何子进程只有一个父进程,而且子进程总是可以通过调用 getppid 取得父进程的进程 ID。相反,父进程可以有很多子进程,而且无法获取各个子进程的进程 ID。如果父进程想要跟踪所有子进程的进程 ID,那么它必须记录每次调用fork的返回值。另外,进程ID 0 总是由内核交换进程使用,所以一个子进程的进程 ID 不可能为 0。子进程和父进程继续执行
fork调用之后的指令。子进程是父进程的副本。例如,子进程获得父进程数据空间、堆和栈的副本。父、子进程并不共享这些存储空间部分。父、子进程共享代码段。另外,需要注意的是,子进程并不会继承父进程的所有属性(如文件锁),详细请参考《Unix 环境高级编程》第 8.3 节“函数 fork”。由于在
fork之后经常跟随着exec,所以现在的很多实现并不执行一个父进程数据段、堆和栈的完全复制。作为替代,使用了写时复制(Copy-On-Write, COW)技术。这些区域由父、子进程共享,而且内核将它们的访问权限改变为只读的。如果父、子进程中的任一个试图修改这些区域,则内核只为修改区域的那块内存制作一个副本,通常是虚拟存储器系统的一“页”。使
fork失败的两个主要原因是:1)系统中已经有太多的进程(通常意味着某个方面出了问题);2)实际用户的进程总数超过了系统限制。
样例程序分析
样例程序如下:
1 |
|
程序的运行结果如下图所示: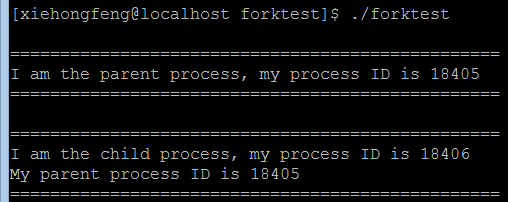
按照惯常,程序按顺序执行,最终输出应该只有 if…else if…else 中一个条件下的结果,但很明显我们这边输出了两个条件下的结果。具体原因在于通过fork函数创建的子进程也会(写时)复制父进程的存储空间(数据、堆、栈等,包括程序计数器),创建了属于自己的存储空间,并从fork函数后开始执行。利用pstree命令可以看到子进程(ID 18406)确实继承自父进程(ID 18405):
一般来说,在 fork 之后是父进程先执行还是子进程先执行是不确定的,这取决于内核所使用的调度算法。在上述程序中,父进程先执行,子进程在其之后执行。
对于子进程在刚创建时执行的是父进程,原因在于子进程刚被创建时并没有自己的代码和数据,只好执行父进程的代码和利用父进程的数据;而一旦子进程加载(execve)了属于自己的代码和数据,就开始执行自己的代码。
关于 fork 函数,还可参考陈皓的博客一个 fork 的面试题。
execve 系统调用
execve函数是exec系列函数(总共 7 种)中的一种。
用fork函数创建子进程后,子进程往往要调用一种exec函数以执行另一个程序(可执行目标文件)。当进程调用一种exec函数时,该进程执行的程序完全替换为新程序,而新程序则从其 main 函数开始执行。因为调用exec并不创建新进程,所以前后的进程 ID 并未改变。exec函数只是用磁盘上一个全新的程序替换了当前进程的正文、数据、堆和栈端。
在很多 UNIX 实现中,exec 7 种函数中只有execve是系统调用,另外 6 个只是库函数,它们最终都要调用该系统调用。这 7 种函数的关系如下: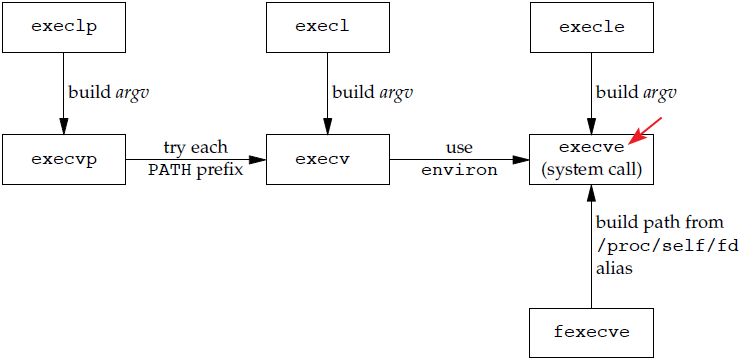 图片来源:《Unix 环境高级编程》
图片来源:《Unix 环境高级编程》
利用execve系统调用加载并运行可执行目标文件a.out的步骤如下(参考自《深入理解计算机系统》第 9.8.3 节“再看 execve 函数”):
- 删除已存在的用户区域。删除当前进程虚拟地址空间的
用户部分中的已存在的虚拟内存区域结构(即vm_area_struct结构体,见后文“虚拟内存区域 VMA”部分)。 - 映射私有区域。为新程序的文本、数据、bss、和栈区域创建新的虚拟内存区域结构(即
vm_area_struct结构体)。所有这些新的区域都是私有的、写时拷贝的。文本和数据区域被映射为a.out中的文本和数据区。bss 区域是请求二进制零的,映射到匿名文件,其大小包含在a.out中。栈和堆也是请求二进制零的,初始长度为零。下图概括了私有区域的不同映射。 - 映射共享区域。如果
a.out程序与共享对象(或目标)链接,比如标准 C 库 libc.so,那么这些对象都是动态链接到这个程序的,然后再映射到用户虚拟地址空间中的共享区域内。 - 设置程序计数器(PC)。execve 做的最后一件事就是设置当前进程上下文中的程序计数器,使之指向文本区域的入口点。
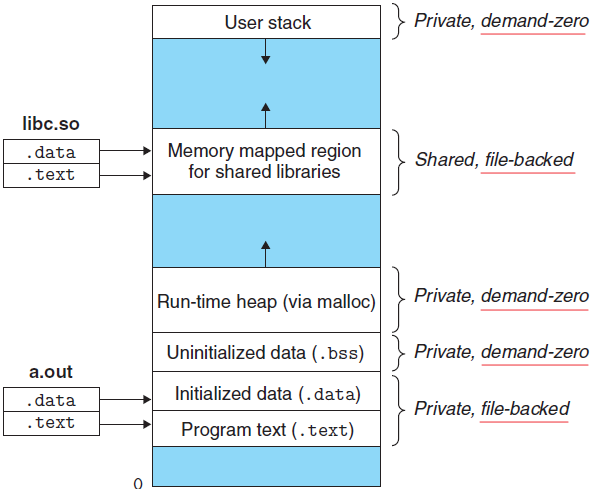 进程虚拟地址空间。图片来源:《深入理解计算机系统》
进程虚拟地址空间。图片来源:《深入理解计算机系统》
关于execve还可参看《深入理解计算机系统》第 8.4.5 节“加载并运行程序”。
子进程虚拟地址空间初始化
在开始之前,我们先看看一个进程运行时的“虚拟地址空间”是怎么样的。
虚拟地址空间
《深入理解计算机系统》第 7.9 节“加载可执行目标文件”对进程运行时虚拟地址空间有一个大概的描述:
每个 Unix 程序都有一个运行时存储器映像,类似于下图所示的那样。在 32 位 Linux 系统中,代码段总是从地址 0x0804 8000 开始处开始。数据段是在接下来的下一个 4KB 对齐的地址处。运行时堆在读/写段之后接下来的第一个 4KB 对齐的地址处,并通过调用 malloc 库函数往上增长。还有一个段是为共享库保留的。用户栈总是从最大的合法用户地址开始向下增长的(向低存储器地址方向增长)。从栈的上部开始的段是为操作系统驻留存储器部分(也就是内核)的代码和数据保留的。
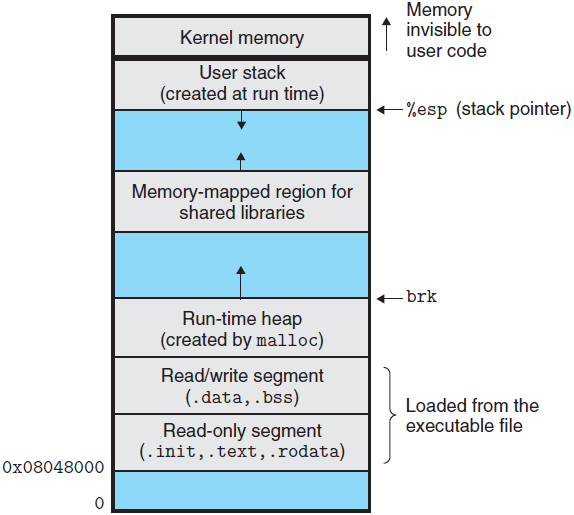 图片来源:《深入理解计算机系统》
图片来源:《深入理解计算机系统》
虚拟地址空间本质
任务描述符
- 注意:跟任务描述符段 TSS 不一样。
在 Linux 0.11 版本内核,对进程已经有一个明确的结构体——任务描述符(Task Descriptor)来描述它,但不够完整(缺少对内存描述符结构体mm_struct的指向)。这里我们采用 Linux 2.4.37 版本内核的任务描述符结构体定义:
1 | struct task_struct { |
在本文,比较重要的是该进程结构体还有一个指针mm指向了描述虚拟地址空间(暂不考虑内核映射)的内存描述符结构体mm_struct。
内存描述符
但在 Linux 0.11 版本内核,对虚拟地址空间并没有用比较明确的数据结构来表示它。不过在 Linux 2.4.37 版本内核中,对虚拟地址空间已经有很明确的数据结构——内存描述符(Memory Descriptor)结构体mm_struct来表示它:
1 | struct mm_struct { |
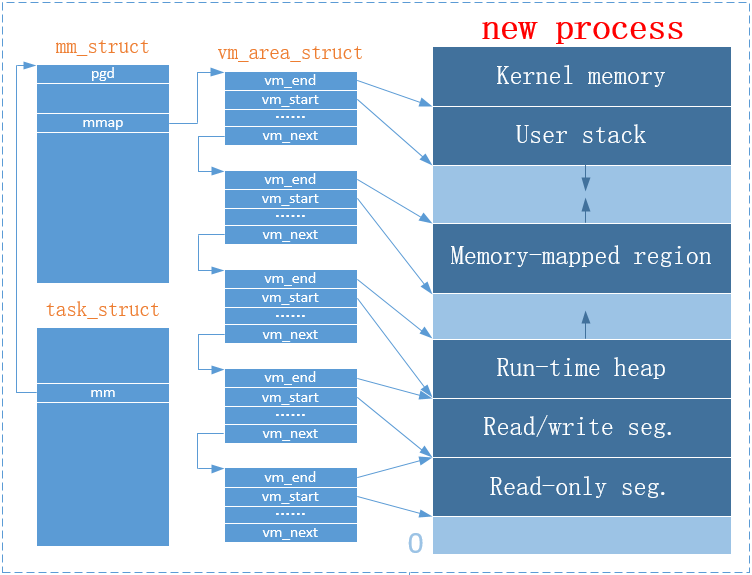
任务描述符和内存描述符之间的关系可用下图表示: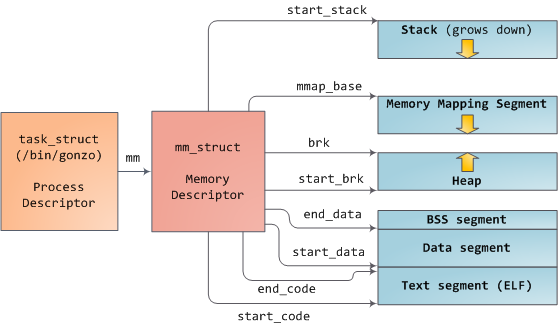 图片来源
图片来源
注意:进程虚拟地址空间的段跟可执行目标文件的段是不一样的。对虚拟地址空间这些段的属性描述放在可执行目标文件的 Segment header table 段,详细请参考上一博文的“可执行目标文件”部分。
从上图可以看出,内存描述符将进程虚拟地址空间分成了不同的段,并且对这些段的开始或结束地址进行了限定。但在这里,我们还漏了一个更加重要的vm_area_struct结构体指针mmap——建立虚拟地址空间与可执行目标文件、共享库之间的映射。
虚拟内存区域 VMA
vm_area_struct结构体描述了虚拟地址空间中的一块连续的区域,叫做虚拟内存区域(VMA, Virtual Memory Area)。同一虚拟内存区域内的代码或数据共享某些特性,如特权级。
vm_area_struct结构体定义如下:
1 | /* |
下图很好描述了该结构体的作用:它既可以将可执行目标文件的段映射到虚拟地址空间内的不同的段,也可以将共享库映射到虚拟地址空间的共享库区域;同时还负责对堆栈映射的管理。关于这部分,还可参考《深入理解计算机系统》第 9.7.2 节“Linux 虚拟存储器系统”。
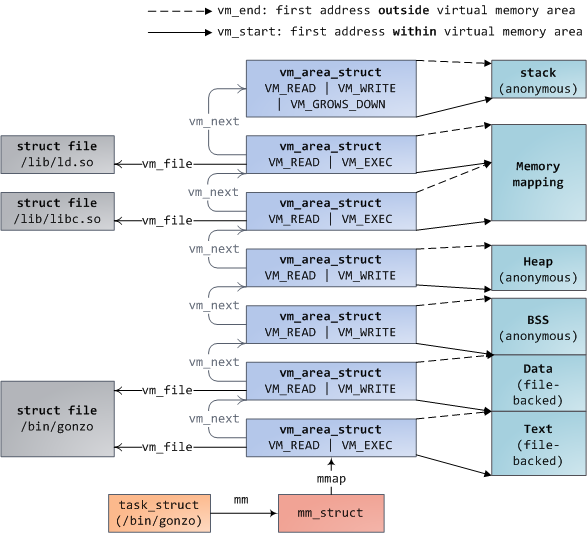 图片来源
图片来源 另外,我们在 Linux 下还可以通过查看
/proc/<PID>/maps获取 ID 号为 PID 的进程的虚拟地址空间的虚拟内存区域及其映射的文件和共享库,如: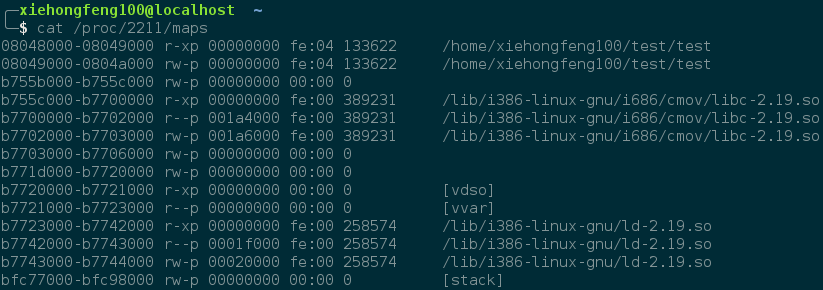
上图各属性从左到右分别是:address perms offset dev inode pathname,详细解释如下:address- This is the starting and ending address of the region in the process’s address spacepermissions- This describes how pages in the region can be accessed. There are four different permissions: read, write, execute, and shared. If read/write/execute are disabled, a ‘-‘ will appear instead of the ‘r’/‘w’/‘x’. If a region is not shared, it is private, so a ‘p’ will appear instead of an ‘s’. If the process attempts to access memory in a way that is not permitted, a segmentation fault is generated. Permissions can be changed using the mprotect system call.offset- If the region was mapped from a file (using mmap), this is the offset in the file where the mapping begins. If the memory was not mapped from a file, it’s just 0.device- If the region was mapped from a file, this is the major and minor device number (in hex) where the file lives.inode- If the region was mapped from a file, this is the file number.pathname- If the region was mapped from a file, this is the name of the file. This field is blank for anonymous mapped regions. There are also special regions with names like [heap], [stack], or [vdso]. [vdso] stands for virtual dynamic shared object. It’s used by system calls to switch to kernel mode. Here’s a good article about it.
You might notice a lot ofanonymous regions. These are usually created by mmap but are not attached to any file. They are used for a lot of miscellaneous things like shared memory or buffers not allocated on the heap. For instance, I think the pthread library uses anonymous mapped regions as stacks for new threads.
- 到这里为止
mmap指向的vm_area_struct结构体链表只保存了可执行目标文件的段到虚拟地址空间和共享库到虚拟地址空间的映射关系,真正的指令和数据还没有装入内存。我们把指令和数据装载放到最后“缺页异常处理”部分进行阐述。
小结
从以上粗略的分析中,我们可以知道,虚拟地址空间(暂不考虑内核映射)本质上是就是一个结构体(mm_struct),它记录的是映射关系而不是具体的代码或者数据。在应用程序的 main 函数被调用前,它记录的是虚拟地址空间与可执行目标文件、共享库之间的映射关系,但此时真正的代码和数据并未加载到内存;在 main 函数被调用后,(有需要的时候)通过操作系统的页错误处理程序,将真正的代码和数据调入内存,开始建立虚拟地址空间与内存之间的映射关系。
跳转到 _start
通过前边的步骤,加载器已经加载好可执行目标文件,接下来就是将 CPU 控制权交给应用程序,让应用程序开始执行。但应用程序并不是从 main 函数开始执行的,而是从_start处开始执行的。《程序员的自我修养》第 11.1 节“入口函数和程序初始化”有一个比较简要的说明:
- 操作系统装载完程序之后,首先运行的代码并不是 main 的第一行,而是某些别的代码,这些代码负责准备好 main 函数执行所需要的环境,并且负责调用 main 函数,这时候你才可以在 main 函数里放心大胆第写各种代码:申请内存、使用系统调用、触发异常、访问 I/O。在 main 返回后,它会记录 main 函数的返回值,调用 atexit 注册的函数,然后结束进程。
- 运行这些代码的函数称为入口函数或入口点(Entry Point),视平台不同而有不同的名字。程序的入口点实际上是一个程序的初始化和结束部分,它往往是运行库的一部分。一个典型的程序运行步骤大致如下:
- 操作系统在创建进程后,把控制权交到了程序的入口,这个入口往往是运行库中的某个入口函数。
- 入口函数对运行库和程序运行环境进行初始化,包括堆、I/O、线程、全局变量构造等等。
- 入口函数在完成初始化之后,调用 main 函数,正式开始执行程序主体部分。
- main 函数执行完毕以后,返回到入口函数,入口函数进行清理工作,包括全局变量析构、堆销毁、关闭 I/O 等,然后进行系统调用结束进程。
在_start处的启动代码(startup code)是在目标文件ctrl.o中定义的,对所有的 C 程序都一样。ctrl.o伪代码如下(对 C++ 可能不一样):
1 | /* Referrence: 《深入理解计算机系统》第 7.9 节“加载可执行目标文件” */ |
在《程序员的自我修养》第 11.1.2 节“入口函数如何实现”对_start处的启动代码有详细的源码分析,值得参考。还有可参考《UNIX 环境高级编程》第 7 章“进程环境”。
缺页异常处理
该部分参考自《深入理解计算机系统》第 9.7.2 节“Linux 虚拟存储器系统”。
当 MMU(Memory Management Unit)试图翻译某个虚拟地址 A 发生缺页时触发一个缺页异常。这个异常导致控制转移到内核的缺页处理程序,处理程序随后就执行下面的步骤:
- 虚拟地址 A 是合法的吗?换句话说,A 在某个虚拟内存区域(VMA)内吗?为了回答这个问题,缺页处理程序搜索
vm_area_struct结构体链表,把 A 和每个vm_area_struct结构体中的 vm_start 和 vm_end 作比较。如果这个指令不合法,那么缺页处理程序就触发一个段错误,从而结束进程。 - 试图进行的存储器访问是否合法?换句话说,进程是否可读、写或者执行这个区域内页面的权限。如果试图进行的访问不合法,将会触发一个保护异常,从而终止这个进程。
- 此刻,内核知道了这个缺页是由于对合法的虚拟地址进行合法的操作造成的。它是这样处理这个缺页的:选择一个
牺牲页面,如果这个牺牲页面被修改过,那么就将它交换出去,换入新的页面并更新页表。当缺页处理程序返回时,CPU 重新启动引起缺页的指令,这条指令将再次发送 A 到 MMU。这次,MMU 就能够正常地翻译 A,而不会发生缺页异常。
上边三种情况可用例图表示如下: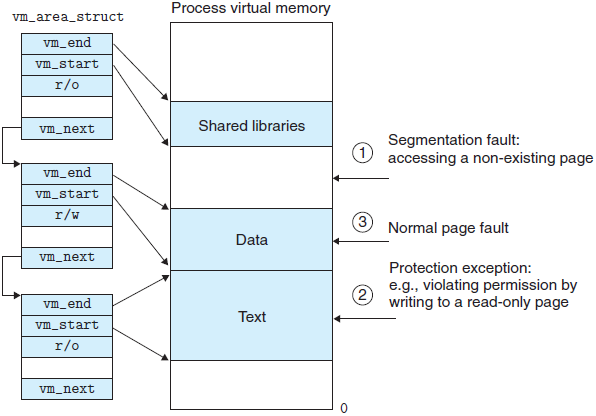
大总结
还是来张图吧,直接又形象: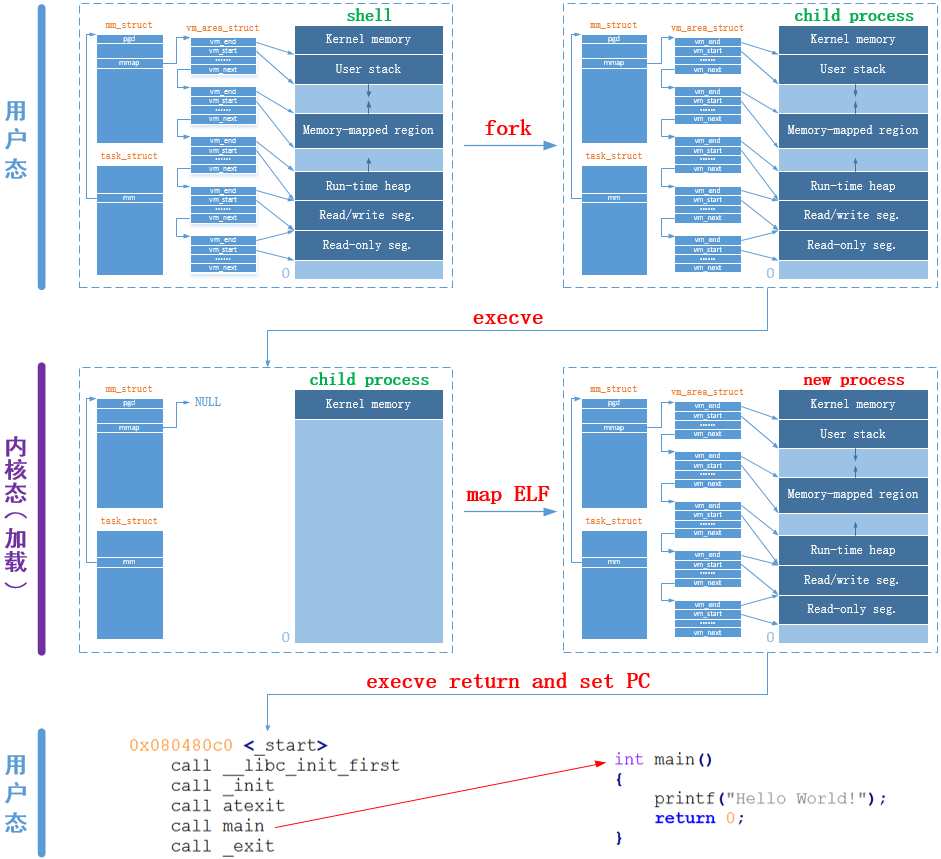
大图细节的地方不够清晰,将其中一个小图放大如下: