
Linux 0.11 初始化好设备环境和激活进程 0 后就开始创建进程 1。接下来几篇博文将关注进程 1 的创建及执行。
注:比较完整的进程创建案例可参考《Linux 内核设计的艺术》(第 2 版)第 6.3 节“一个用户进程从创建到退出的完整过程”。这个小节写的相当不错!
调用 fork
进程 0 现在已经工作在 3 特权级,即进程状态,可以调用 fork 函数创建子进程。它创建的第一个子进程是进程 1:
1 | // include/unistd.h ---------------------------- // unistd -> unix standard |
int 0x80 中断发生后,CPU 从 3 特权级的进程 0 代码调到 0 特权级内核代码执行。需要注意的是,此时 ss esp eflags cs eip 已经按序压到进程 0 的内核栈,它们都是 copy_process() 函数的参数。
题外:进程的用户栈和内核栈
对进程的用户栈和内核栈,博文进程内核栈、用户栈有一段简明的阐述:
- 进程的栈
- 内核在创建进程的时候,在创建 task_struct 的同时,会为进程创建相应的栈。
每个进程会有两个栈,一个用户栈,存在于用户空间,一个内核栈,存在于内核空间。当进程在用户空间运行时,CPU 堆栈指针寄存器里面的内容是用户堆栈地址,使用用户栈;当进程在内核空间时,CPU 堆栈指针寄存器里面的内容是内核栈空间地址,使用内核栈。
- 进程用户栈和内核栈的切换
- 当进程因为中断或者系统调用而陷入内核态时,进程所使用的堆栈也要从用户栈转到内核栈。
进程陷入内核态后,先把用户栈的地址保存在内核栈之中,然后设置堆栈指针寄存器的内容为内核栈的地址,这样就完成了用户栈向内核栈的转换;当进程从内核态恢复到用户态时,将保存在内核栈里面的用户栈的地址恢复到堆栈指针寄存器即可。这样就实现了内核栈和用户栈的互转。- 那么,我们知道从内核态转到用户态时,用户栈的地址是在陷入内核的时候保存在内核栈里面的,但是在陷入内核的时候,我们是如何知道内核栈的地址的呢?
- 关键
在进程从用户态转到内核态的时候,进程的内核栈总是空的。这是因为,当进程在用户态运行时,使用的是用户栈,当进程陷入到内核态时,内核栈保存进程在内核态运行的相关信息,但是一旦进程返回到用户态后,内核栈中保存的信息无效,会全部恢复,因此每次进程从用户态陷入内核的时候得到的内核栈都是空的。所以在进程陷入内核的时候,直接把内核栈的栈顶地址给堆栈指针寄存器就可以了。
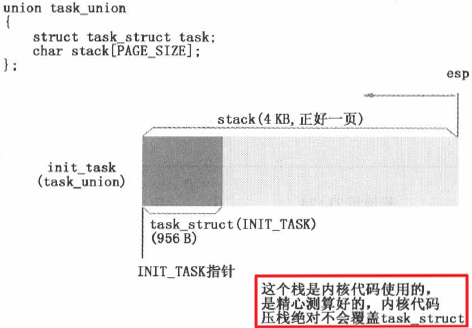
具体地,在 Linux 0.11,内核用于管理进程的结构 task_union 在提供了进程描述符 task_struct 的存储空间同时,也提供了进程内核栈的空间,如进程 0 的 task_union 如下图所示;而对于进程的用户栈,要从虚拟地址空间角度来理解。
 图片来源:《Linux 内核设计的艺术》
图片来源:《Linux 内核设计的艺术》
对于 task_union,《Linux 内核设计的艺术》有一个简要的评论:
task_union 的设计颇具匠心。前面是 task_struct,后面是内核栈,增长的方向正好相反,正好占用一页,顺应分页机制,分配内存非常方便。而且操作系统设计者肯定经过反复测试,保证内核代码所有可能的调用导致压栈的最大长度都不会覆盖前面的 task_struct。因为内核代码都是操作系统设计者设计的,可以做到心中有数。相反,假如用这个方法为用户进程提供栈空间,恐怕要出大问题了。
另外,除了进程 0,其他进程的内核栈都是建立在内存 1MB 区域之外,即内核代码和数据区域之外的页面(copy_process 函数 -> p = (struct task_struct *) get_free_page())。但这个页面都没有映射到进程的线性地址空间(即没有调用 put_page 函数),所以进程是无法访问这个页面的,只有内核可以访问。
调用 sys_fork
在之前博文 Linux 内核学习笔记:初始化程序(第 3 部分),我们知道 int80 绑定的中断服务程序是 system_call,所以 fork 函数还是要通过 system_call 来实现。不过 system_call 是一个总的入口服务程序,对于具体的服务还是要由具体的服务程序来完成,如 fork 函数最终要通过具体的服务程序 _sys_fork 来实现。关于 fork 函数的执行流程如下代码所示:
1 | // kenel/system_call.s ------------------------- |
代码的执行过程如下图所示: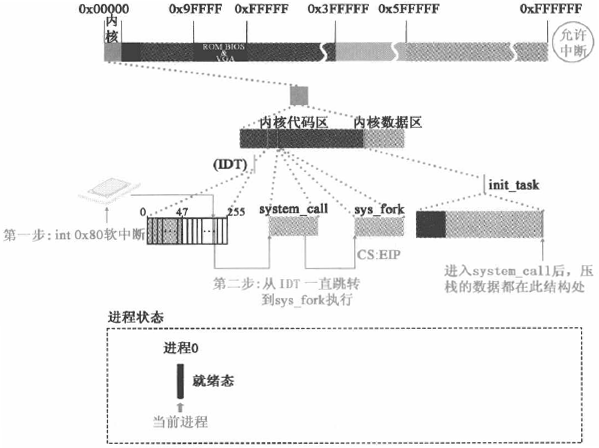 图片来源:《Linux 内核设计的艺术》
图片来源:《Linux 内核设计的艺术》
注意:在调用 _sys_fork 之前,进程 0 的内核栈又按序压入了 ds es fs edx ecx ebx。另外,调用 call _sys_call_table(,%eax,4) 本身也会压栈保护现场。这个压栈体现在 _sys_fork 调用的 copy_process 函数的第 6 个参数 long none。
调用 find_empty_process
进入 _sys_fork 服务程序后,第一步就是为进程 1 寻找一个可用的进程号和 task[64] 中的一个可用位置(任务号)。这个过程是由 find_empty_process 函数来实现的,其定义如下:
1 | // kenel/fork.c -------------------------------- |
上述代码中,全局变量 last_pid 用来存放系统自开机以来累计的进程数,也将此变量用作新建进程的进程号。
注意:在调用 copy_process 函数之前,进程 0 的内核栈又按序压入了 gs esi edi ebp eax,它们都是 copy_process 函数的参数。其中 %eax 保存的是 find_empty_process 函数返回的进程 1 的任务号(注意跟进程号的区别),是 copy_process 函数的第一个参数 nr。
调用 copy_process
对于函数参数压栈,《Linux 内核设计的艺术》对此有一简单说明:
一个函数的参数不是由函数定义的,而是由函数定义以外的程序通过压栈的方式“做”出来的,是操作系统底层代码与应用程序代码写作手法的差异之一。运行时,C 语言的函数的参数存在于栈中。模仿这个原理,操作系统的设计者可以将前面程序所压栈的值,按序“强行”认定为函数的参数;当 call 这个函数时,这些值就可以当做参数用。
这说明,之前压栈的数可作为 copy_process 函数的实际输入参数。之前压栈(进程 0 内核栈)的数为:
1 | // 高地址 -> 低地址 |
按“低地址 -> 高地址”方向将这些数一一“弹出”(不是真正弹出,这些数还留在栈中),作为 copy_process 函数的参数:
1 | // kenel/fork.c -------------------------------- |
调用 get_free_page
注:对于内核而言,它不按用户态下的分页系统来寻址,而是按照“段(选择子)+偏移”的方法。它能寻址整个内存。
如果能找到空闲页,get_free_page 返回该页在内存中的实际起始位置;反之返回 0。
该函数定义如下:
1 | // mm/memory.c --------------------------------- |
注:
scasb:Scan String Byte 的缩写。还有类似的 scasw。- ecx 控制循环次数
- 每次循环比较 al 与 es:edi (es 为段选择子)所指向内存内容(因为比较的是 Byte,所以用 al)
- 若 EFLAGS 中的方向标志位 DF=0 (使用 cld 指令),则 edi 自增 1 (因为比较的是 Byte,所以递增 1);若 DF=1(使用 std 指令),则 edi 自减 1
- repne 表示当 ecx > 0 并且 ZF=0 (al 与 es:edi 所指向内存内容不相等)时,循环继续;反之停止
- 在这个程序开头,al=0,ecx=PAGING_PAGES,es=0x10(选择子,在 _system_call 中所赋的值),edi=mem_map+PAGING_PAGES-1,DF=1(std)。所以,程序开头的”std ; repne ; scasb”表示的是反方向扫描串,al 与 es:edi 所指向内存内容不等则重复,直到条件不满足(ecx<=0 或者 ZF=1)。实际上,它表示的是按 mem_map[PAGING_PAGES-1]…mem_map[0] 方向扫描,如果找到值为 0 的 mem_map 项(表示该项指向的物理页没有使用过),则停止循环。反之,则说明已经没有可用的空闲页。
stosl:每次保存的是 4 个字节。- ecx 控制循环次数
- 每次循环将 eax 的值保存到 es:edi (es 为段选择子)指向的内存
- 若 EFLAGS 中的方向标志位 DF=0 (使用 cld 指令),则 edi 自增 4 (因为每次操作大小是 Long,所以递增 4);若 DF=1(使用 std 指令),则 edi 自减 4
- rep 表示当 ecx>0 时,循环继续;反之停止
- 在这个程序中,每循环 1 次,清零的内存范围是 4 字节;循环 1024 次,清零的内存范围是 1024*4=4096 字节,恰好是一个页。而且该页是主内存区最末端的页。
- 字符串处理指令
- lodsb、lodsw:把 ds:si 指向的存储单元中的数据装入 al 或 ax,然后根据 df 标志增减 si
- stosb、stosw:把 al 或 ax 中的数据装入 es:di 指向的存储单元,然后根据 df 标志增减 di
- movsb、movsw:把 ds:si 指向的存储单元中的数据装入 es:di 指向的存储单元中,然后根据 df 标志分别增减 si 和 di
- scasb、scasw:把 al 或 ax 中的数据与 es:di 指向的存储单元中的数据相减,影响标志位,然后根据 df 标志分别增减 si 和 di
- cmpsb、cmpsw:把 ds:si 指向的存储单元中的数据与 es:di 指向的存储单元中的数据相减,影响标志位,然后根据 df 标志分别增减 si 和 di
- rep:重复其后的串操作指令。重复前先判断 cx 是否为 0,为 0 就结束重复,否则 cx 减 1,重复其后的串操作指令。主要用在movs和stos 前。一般不用在 lods 前。
- 上述指令涉及的寄存器:段寄存器 ds 和 es、变址寄存器 si 和 di、累加器 ax、计数器 cx
- 涉及的标志位:DF、AF、CF、OF、PF、SF、ZF
复制父进程 task_struct
这部分代码如下:
1 | // kenel/fork.c -------------------------------- |
上述代码中的 current 指向当前进程的 task_struct 的指针,当前进程是进程 0。*p = *current 表示将父进程的 task_struct 复制给子进程。这是父子进程创建机制的重要体现。这行代码执行后,父子进程的 task_struct 完全一样。如下图所示: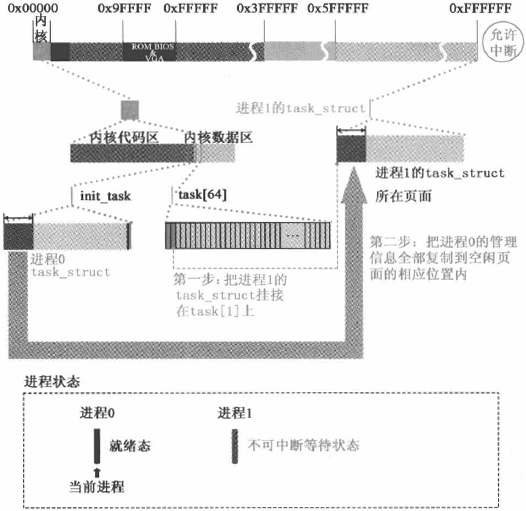 图片来源:《Linux 内核设计的艺术》
图片来源:《Linux 内核设计的艺术》
不过需要注意的是,进程 0 的 task_struct 的信息不一定完全适合进程 1,所以需要进行一些调整:
1 | // kenel/fork.c -------------------------------- |
设置分页管理系统
这部分代码如下:
1 | // kenel/fork.c -------------------------------- |
设置代码、数据段基地址
这部分代码如下:
1 | // kenel/fork.c -------------------------------- |
这部分代码是提取进程 0 的代码段、数据段的段基址以及段限长的信息,并设置进程 1 的代码段、数据段的段基址。下边分两部分对这段代码进行解释:
对于
_get_base和_set_base两个函数的汇编,只要参照段描述符的结构就足够了: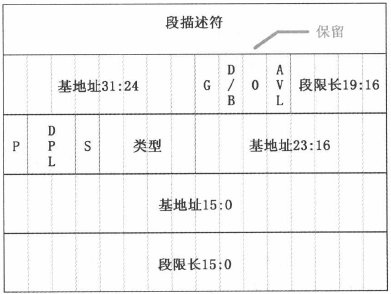 图片来源:《Linux 内核设计的艺术》
图片来源:《Linux 内核设计的艺术》
(注:也可参考之前博文 Linux 内核学习笔记:预备知识之“存储器管理基础”“存储段描述符”部分)get_limit函数的汇编有点难理解。这个函数的参数 segment 是段选择子。当 segment 为 0x0f 时,表示选中进程 0 的 LDT 中的代码段;0x17 表示选中进程 0 的 LDT 中的数据段。通过lsll命令取出来的段限长需要加 “1” 才是真正的段限长。例如,当 segment 为 0x0f (该代码段描述符定义在 INIT_TASK),求出的段限长为 636KB,而实际上应该是 640KB,所以需要加 “1”: (unsigned long)(636KB+1)=640KB。Linux 0.11 内核中人工定义系统支持的最大任务数位 64,每个进程空间的虚拟地址空间是 64MB,并且每个进程的虚拟地址起始位置是”任务号*64MB”。因此所有进程所使用的虚拟地址空间是 64MB*64=4GB,如下图所示:
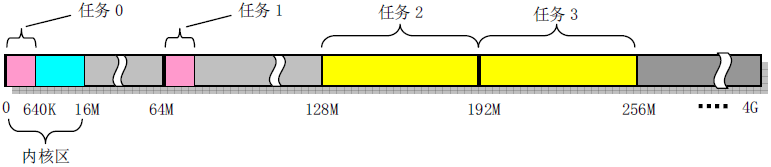 图片来源:《Linux 内核设计的艺术》
图片来源:《Linux 内核设计的艺术》 Linux 0.11 进程虚拟地址空间: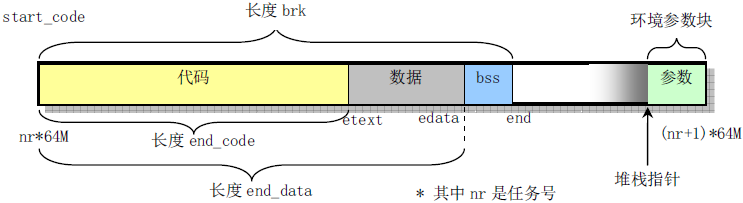 图片来源:《Linux 内核设计的艺术》
图片来源:《Linux 内核设计的艺术》 但需要注意的是,
Linux 0.11 的实际物理内存如下图: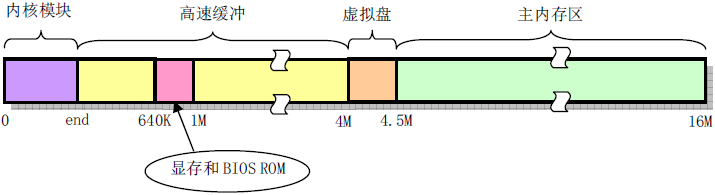 图片来源:《Linux 内核设计的艺术》
图片来源:《Linux 内核设计的艺术》
复制页表
Linux 0.11 中只有一个页表目录,为所有进程共享。每个进程都有自己对应的页表目录项,也即都有自己对应的页表。
复制页表的代码如下:
1 | // kenel/fork.c -------------------------------- |
对 copy_page_tables 函数,上边已经有详细的注释。其中,需要注意的是:
boot/head.s 文件设置并初始化了分页管理系统;而 sched_init() 函数虽然对进程 0 进行了初始化,但并没有设置进程 0 的分页系统。
对于进程 0,其起始线性地址(0x0000 0000)刚好能够映射到页表目录的第 1 项;整个虚拟地址空间(64MB)可以映射到页表目录的第 1 ~ 16 项。而这些页表目录项已经在 boot/head.s 设置好,所以就相当于进程 0 的页表系统早在进程 0 被创建之前就已经设置好了。进程 1 映射的第 1 个页表目录项在页表目录中算第 17 个。Linux 0.11 只有一个页表目录页面复制时采用了
写时复制的技术进程 1 只复制了进程 0 页表的前 160 项。这 160 项能表示的实际内存范围为 160*4KB=640KB,恰好是实际内存中“内核+缓冲区低端”所占的区域
在 Linux 0.11,物理内存 1MB (LOW_MEM) 并不采用用户态下的分页系统来寻址,而是按照“段(选择子)+偏移”的方法。1MB 以上,才采用分页管理系统。这里还有一个没有解决的问题是:size = ((unsigned) (size+0x3fffff)) >> 22; 中的 0x3fffff 是怎么来的?有待下次解决。
copy_page_tables 的执行结果可用下图表示: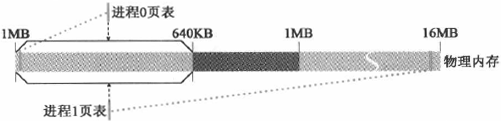 图片来源:《Linux 内核设计的艺术》
图片来源:《Linux 内核设计的艺术》
小结
进程 1 的分页系统设置可用图总结如下: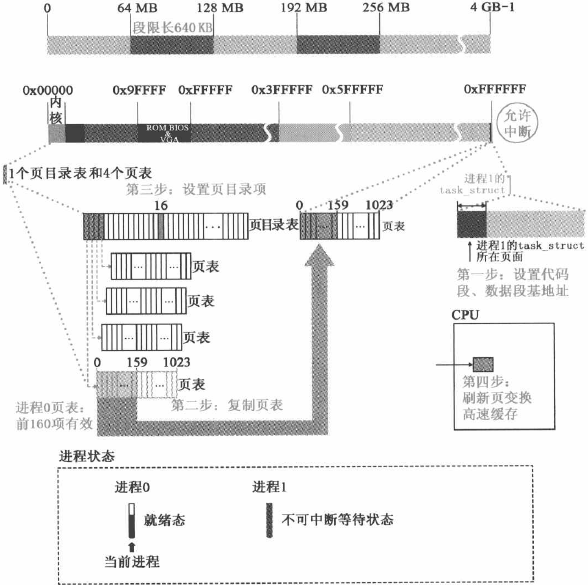 图片来源:《Linux 内核设计的艺术》
图片来源:《Linux 内核设计的艺术》
共享文件
进程 1 共享进程 0 文件的代码如下:
1 | // kenel/fork.c -------------------------------- |
设置 TSS 及 GDT
这部分代码如下:
1 | // kenel/fork.c -------------------------------- |
进入就绪态
将进程 1 的状态设置为就绪态,使它可以参加进程调度:
1 | // kenel/fork.c -------------------------------- |
上述代码返回值 last_pid 保存在寄存器 eax。
返回 fork 函数
返回 sys_fork
从 copy_process 函数返回后,开始执行下边代码:
1 | // kenel/system_call.s ------------------------- |
返回 system_call
sys_fork 返回后,跳转到 system_call 中执行:
1 | // kenel/system_call.s ------------------------- |
返回 fork
system_call 返回后,cs:eip 指向 fork() 中 int 0x80 的下一行,即从 if(__res >=0) 处开始执行:
1 | // include/unistd.h ---------------------------- // unistd -> unix standard |
因为 eax 保存的值是进程 1 的进程号 1,所以 __res >= 0 为真,fork() 函数返回 1,并开始执行下述代码:
1 | // init/main.c --------------------------------- |
上述代码可用下图表示: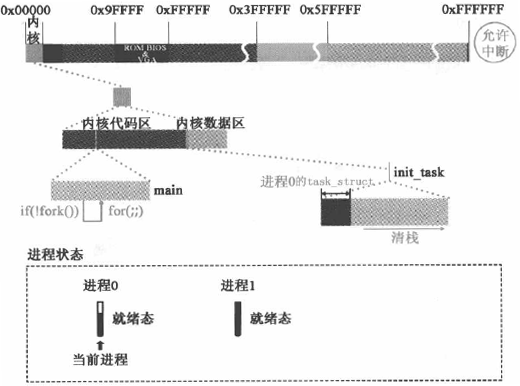 图片来源:《Linux 内核设计的艺术》
图片来源:《Linux 内核设计的艺术》