
数据集可以从 Yelp 官方网站下载得到。我们这里下载的是 SQL 版本,可以直接导入到数据库当中。
原始数据集概况
原始数据集主要包括了 business(商店)、user(用户)、review(评论)、checkin(签到) 4 个数据集,它们各自涵盖的字段可参考官方的文档。
将下载好的 SQL 文件导入到 MySQL 数据库,可以统计一下这些主要数据集的数据条目数量:
可以看出,用户数量达到 1 百多万,意味着用用户评价过的商店来计算计算用户之间的相似度是一个相当大的计算量;评论的处理(如分词、词形还原、词之间相似度计算)也是一大计算量;等等。所以在个人电脑上,为了计算可行性,我们可以挑选一个商店最多的城市作为代表进行分析。下图是拥有商店最多的前20个城市:
假设我们挑选了拥有商店最多的一个城市 Las Vegas,其涵盖数据量如下: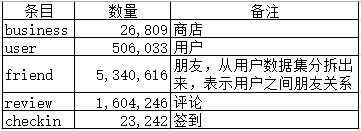
可以看出,即使我们只选择 Las Vegas 这个城市的数据来分析,计算量也是很大的(后续博文中计算用户之间相似度就知道了)。
MySQL 表处理
原始数据集表
用 Navicat 软件的逆向数据库模型功能,我们可以看到几个主要的表结构如下:
这里有几个问题:
- 只有 friend、checkin 表的 id 是自增的,其他表并不是(这会降低表按 id 查询效率),所以我们需要为商店、用户、评论这几张表增加一个自增字段
- 表与表之间没有建立外键关联,存在数据冗余。建立外键之后,之前需填完整字符串的字段就可以改成只填关联表的自增 id,如表 review 的 user_id 字段外键关联了 user 表的 id 列,那表 review 的 user_id 字段就不用再填一大串的字符串了,而是一个 user 表的自增 id。另外,没有外键也不便于后续的开发(不便于在 Django 框架中使用反向引用功能)
表处理
这里我们针对以上的问题进行处理。下边以表 business 为例进行说明。
首先,为该表添加自增字段 id:
1 | # 先重命名原 id 字段为 business_id |
其次,将其他表关联到 business 表,如将 review 表原 business_id 字段的值改为对应的 business 表中的 id 值,并添加外键到 business 表:
1 | # 为加快接下来字段比较,可以先添加一个索引,并将 business_id 字段更名 business_id_old |
需要注意的是,我们建立外键的时候,MySQL(InnoDB 引擎)会自动帮我们建立索引,具体可参考官方说明:
MySQL requires indexes on foreign keys and referenced keys so that foreign key checks can be fast and not require a table scan. In the referencing table, there must be an index where the foreign key columns are listed as the first columns in the same order. Such an index is created on the referencing table automatically if it does not exist.
所以,我们用于外键的 review 表 business_id 字段就已经自动建立了索引,我们就没必要手动创建了。
拆表
对于 review 表而言,我们可以简单看下其 text 字段内容:
这个 text 字段比较占用间且影响查询的 ,所以采用拆表方式,将 review 表拆成两个表。具体是新建一个 review_text 表用于存放 text,然后在 review 表新增一个字段 text_id 外键到该表:
1 | CREATE TABLE review_text ( |
表处理后概览
以上全部处理完毕后,可以看到这样的表关系图(这张图是后来将表改名之后截的图,都加了一个 base_ 前缀,但不影响情况说明):
数据导出
因为在 MySQL 中,对数据处理还是有点不方便(如对评论文本处理),所以这里将上文提到的几个主要表的数据都导出成 CSV 文件,方便用 pandas、numpy 等库进行分析。下边是导出命令:
1 | SELECT id,user_id INTO OUTFILE '/tmp/user_with_db_id.csv' FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n' FROM backend_user; |